
OpenAI 在继续堆 GPT-6 的参数,Google 的 Gemini还在扩大上下文窗口,国内的各大厂商也在卷模型规模——动辄几千亿、上万亿参数。整个行业的叙事只有一个:越大越强。
然后,一个只有8B(80 亿)参数的模型,同时登上了 Nature 正刊和 Science 的报道。
8B是什么概念?现在主流的大模型动辄500B、1000B 起步。8B 在它们面前,大概相当于一个骑共享单车的人在F1赛道上跑。
但就是这辆「共享单车」,在「阅读和理解科学文献」这个任务上,跑赢了很多大模型。

这件事背后有个值得聊的问题:在AI领域,「大」真的是唯一的方向吗?

一、OpenScholar 做了什么?
先说清楚,OpenScholar 不是又一个「什么都会一点」的通大模型。它只做一件事——阅读和理解科学论文。
具体来说,它的任务包括:
● 给一篇论文写摘要
● 从一堆论文中找出和某个研究主题相关的
● 回答关于论文内容的具体问题
● 提取论文中的关键信息(方法、数据、结论)
听起来不难?你如果让 ChatGPT 做这些,确实能做。但关键区别在于:科学论文不是普通文本。它们有独特的结构、专业术语、引用关系和论证逻辑。通用大模型面对这些内容时,最大的问题是——它什么都知道一点,但什么都不够深。
OpenScholar 的做法很直接:我用80亿参数,但我只看论文。就像你让一个博士只研究自己的领域,那他在这个领域的深度,大概率超过一个什么书都翻了一下的通才。
二、为什么8B够用?
这是整篇文章最核心的问题。所有人都觉得模型越大越好,那为什么一个「小不点」能在科学任务上表现出色?
我觉得有三个原因。
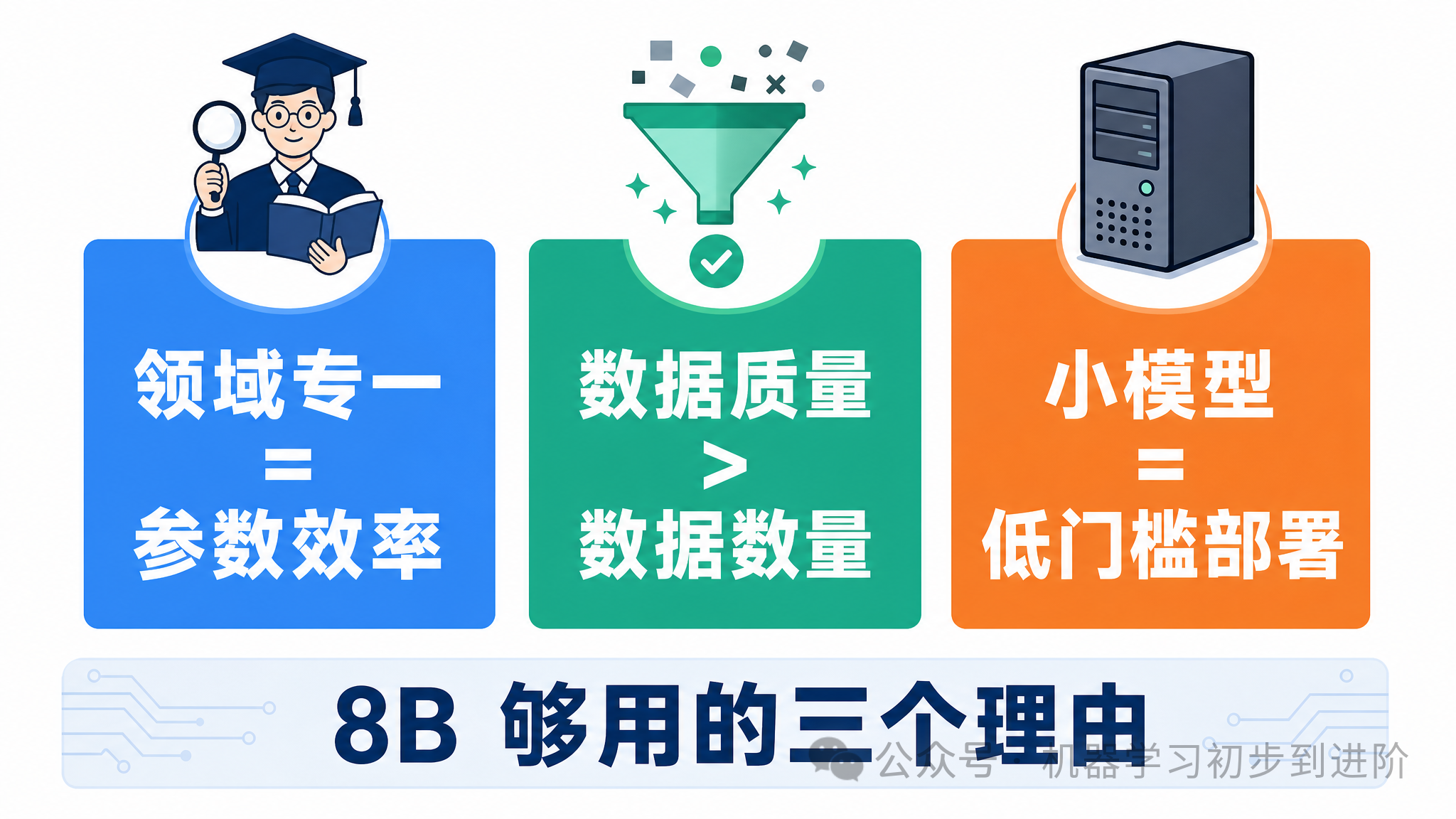
第一,领域专一带来的「参数效率」
大模型的参数多,是因为它要同时学会写诗、编程、聊天、做数学题。它的大部分参数被用来处理「通用能力」——比如理解日常对话的语气、记住世界知识、模仿各种写作风格。
但 OpenScholar 只需要做一件事:读论文。它不需要知道怎么写情书,不需要会讲笑话,不需要帮你润色简历。它的所有参数都用来理解科学文献的结构和语言。这就好比一个只做了十年文献综述的研究助理,虽然知识面不广,但看论文的效率极高。
第二,训练数据的「质量胜过数量」
OpenScholar 的训练数据不是整个互联网——而是经过筛选的科学文献。这意味着它的每一个 token 都是有价值的,没有垃圾信息来「稀释」模型的学习。相比之下,一个大模型虽然看了更多数据,但其中大部分是社交媒体帖子、论坛讨论、新闻标题——这些信息对于理解科学论文来说,用处不大。
用一句糙话说:你看了1000篇论文,比你看了 100 万条微博加 1000 篇论文,在「论文理解」这件事上可能更有效。
第三,小模型的「可部署性」
8B 参数意味着什么?意味着它可以在一台普通的服务器上跑,甚至在一台高配笔记本上也能运行。一个 500B 的模型需要几十个GPU集群,成本是天文数字。而 8B 的模型,很多大学实验室就能部署。
这决定了它能被谁用。如果一个科学 AI 工具只能被有钱的大公司用,那它对科研的帮助是有限的。但如果一个普通实验室也能在自己的机器上跑,那它的实际影响力就大得多。
三、这件事真正有意思的地方在哪
不是因为一个小模型上了 Nature 和 Science 这件事本身,而是因为它暗示了一个更大的趋势:**AI 的未来可能不是「一个模型统治一切」,而是「一堆小模型各干各的活」。**
你看现在的行业格局——所有人都想做一个「万能模型」,能聊天、能画图、能写代码、能做科研、能当客服。这个方向没错,但它有一个隐藏成本:**在每一个具体领域里,它都不够好。**
而 OpenScholar 展示了一条不同的路:与其做一个什么都会的巨人,不如做一个在特定领域里做到极致的专家。这条路的好处是:
● 参数少 → 训练快、部署便宜 → 更多人能用
● 数据精 → 领域深度大 → 专业任务表现更好
● 目标窄 → 评估标准清晰 → 进步可量化
● 开源 → 社区可以复用和改 → 形成生态
其实这跟科研本身很像。你很难找到一个「什么都懂」的科学家——每个科学家都是在一个窄领域里深挖十年,然后在某个点上做出别人做不出的东西。AI 可能也需要走这条路。
四、那我们是不是可以告别大模型了?
别急。不是说大模型没用,也不是说小模型能解决一切。OpenScholar 的优势是建立在「任务定义清晰、领域范围明确」这个前提上的。它的成功恰恰是因为它选择了「科学文献理解」这个具体的、边界清晰的任务。
如果你要一个能写代码、能翻译、能聊天、能画图的全能助手,那大模型确实更合适。但如果你只需要它做一件具体的事,而且你希望它在这件事上做得又深又便宜——那小模型可能就是更好的选择。
我觉得更有趣的未来是:**大模型提供通用能力,小模型在各自领域里做专精。**就像一家医院——全科医生解决常见问题,专科医生处理疑难杂症。两者配合,比只有一个全能医生效果好得多。
写在最后
8B 参数同时上了 Nature 和 Science,这件事最让人兴奋的不是技术参数本身,而是它传递了一个信号:在AI的狂热竞赛中,不是只有「更大」这一个方向值得走。
有时候,「更小、更专、更深」反而能走得更远。
就像科研本身一样——真正改变领域的,往往不是什么都知道一点的人,而是在一个点上挖得足够深的人。AI 可能也需要学会「深耕」,而不是永远在「广撒网」。
参考来源:
• Nature, "OpenScholar: A foundation model for scientific literature" (2026)
• Science, "AI tool for scientific literature review garners attention" (2026)
• Nature Machine Intelligence, Volume 8, Issue 4, April 2026
• Stanford HAI, AI Index Report 2026
• CAS, "2026 Scientific Breakthroughs: Emerging Trends to Watch"
 京公网安备11010502056287号
京公网安备11010502056287号